Hackit 2026 に協賛しました。
第48回競技かるた全国高等学校選手権大会に協賛しました
第48回競技かるた全国高等学校選手権大会に協賛しました。
北國新聞に掲載いただきました。
2026年4月22日付 北國新聞に掲載いただきました。
WEB版はこちら www.hokkoku.co.jp
QuizKnock様に「化学構造式かるた」アプリを取り上げていただきました。
2025年11月26日 Youtube「QuizKnockと学ぼう」チャンネルにて、化学構造式かるたを取り上げていただきました。
化学構造式かるたは、化合物や化学構造式に関する知識をゲーム感覚で楽しく身につけることができる新しいかるた型学習ツールです。
本アプリは兵庫医科大学薬学部の青江麻衣先生と共同で開発いたしました。
また、本アプリは、Beta Computingの「オリジナルかるたアプリ制作サービス」を通じてリリースされました。
無料でダウンロードできますので、この機会にぜひ「化学構造式かるた」をプレイしてみてください。
動画はこちら www.youtube.com
アプリダウンロードはこちらから

オリジナルかるたアプリ制作サービスについてはこちらから betacomputing.co.jp
デジタルアドレス検索アプリ紹介
はじめに
こんにちは。Beta Computing株式会社でソフトウェア開発を担当している國田です。 この記事ではデジタルアドレス検索アプリについてお話しいたします。
デジタルアドレス検索アプリのご紹介
今回は、デジタルアドレスに登録されている住所を検索して表示するだけのシンプルなアプリを作成しました。
デジタルアドレスとは?
デジタルアドレスとは、現在の住所を7桁の英数字に紐づけることで、住所入力の手間を省くことを目的とした取り組みとして日本郵便株式会社が発表したサービスになります。
(※ 弊社は当サービスに運営等では関わってはいません。本アプリについても日本郵便株式会社が提供しているAPIを利用しただけのものになります。)
例えば、弊社の住所は以下ですが
〒 929-0343 石川県河北郡津幡町南中条へ11-4
これをデジタルアドレスに変換すると
VP5-G5YT
となります。このコードを対応Webサイトに入力すると、元の住所が自動で表示されます。住所入力の手間が省けるうえ、入力ミスの防止にもつながります。
さらにデジタルアドレスは、郵便番号では表現できないアパートの部屋番号など、より詳細な住所も指定可能です。
(デジタルアドレスの登録および検索は日本郵便株式会社公式Webサイトでアカウントを登録後に行うことができます。詳しくは以下のリンクをご覧ください。)
デジタルアドレスについて(日本郵便株式会社公式Webサイト)
デジタルアドレス検索アプリの機能
今回開発したアプリの機能は以下になります。
- デジタルアドレスから住所検索
- 郵便番号からも住所検索可能
- 住所および郵便番号のコピー
- 検索履歴の表示
以上の機能で構成されるシンプルなアプリになります。
開発の背景
今回私はとあるFlutterプロジェクトに参画するにあたり、Flutterアプリの開発をキャッチアップする必要がありました。
そのプロジェクトでは、まだ私が触ったことがないライブラリを使用されているとのことでしたので、
API通信やデータベース操作を、そのライブラリを使用して実装してみることにしました。
これらの要素を含む題材として、デジタルアドレスの検索および履歴機能を備えたアプリケーションの開発に取り組むことにしました。
また、本アプリは学習用として開発しましたが、デジタルアドレスに対応していないWebサイト等において、住所入力の手間を軽減する実用的なツールとしての活用も想定しています。
構成図
本アプリは日本郵便株式会社が提供する郵便番号・デジタルアドレスAPIを利用しています。
APIの利用には、先述のデジタルアドレスを取得するためのアカウントとは別途アカウントを取得する必要があります。
詳しくは以下のWebサイトをご覧ください。
また、APIの利用にはWebサイト名や、IPアドレスなどの情報が必要(実装当時)で、基本的には、スマホアプリ等のクライアントアプリからではなく、バックエンドのWebサーバからAPIコールされることを想定されているようでした。 この制約を考慮し、今回はリレーサーバーを用意して検索結果を取得し、それをスマートフォンアプリ上に表示する構成としました。

主な機能
最後にアプリの機能を実際の画面と共に紹介します。
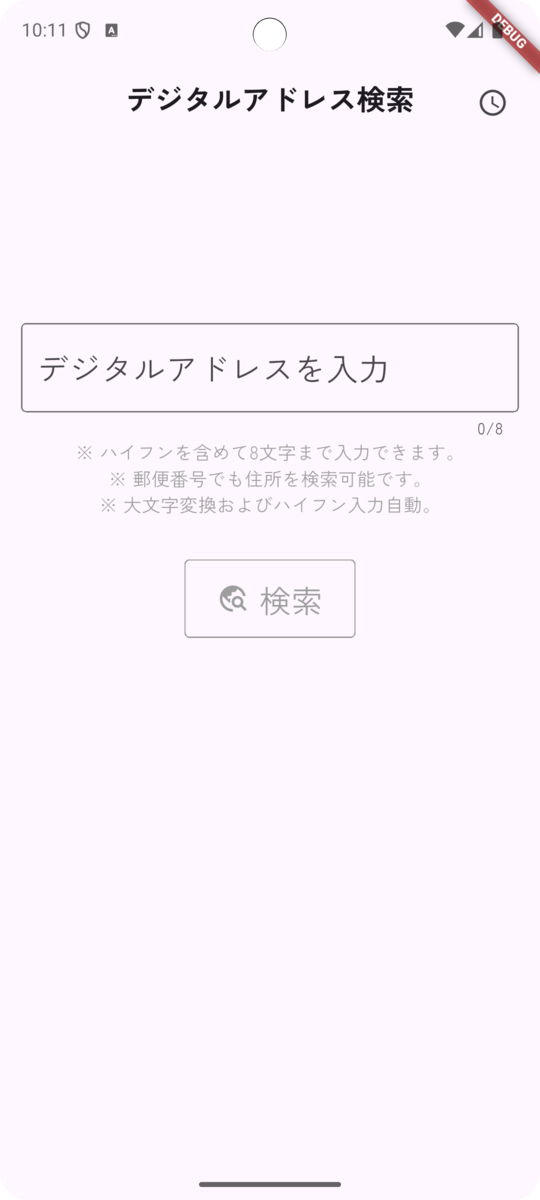
検索画面(ホーム画面)
アプリを開くと以下の画面が表示されます。
この画面からデジタルアドレスを入力して住所を検索することができます。また、郵便番号から検索することもできます。
さらに、入力は自動で大文字化され、ひらがななどは誤入力されないようにしています。
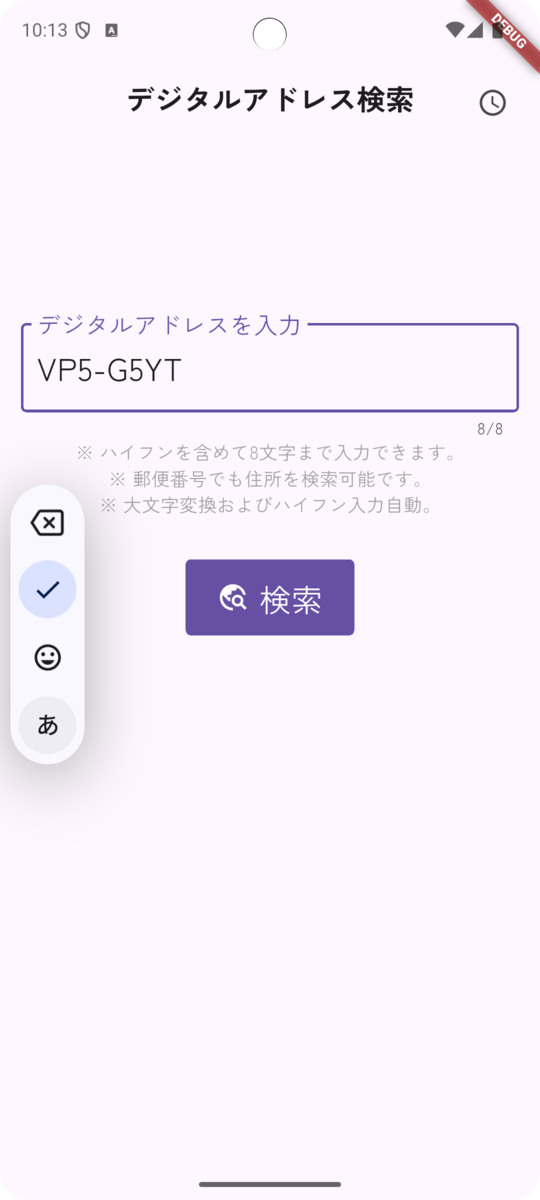
入力例としては以下のような感じです。 7桁の英数字を入力すると検索ボタンが押せるようになり、検索ボタンを押すと検索が実行されます。
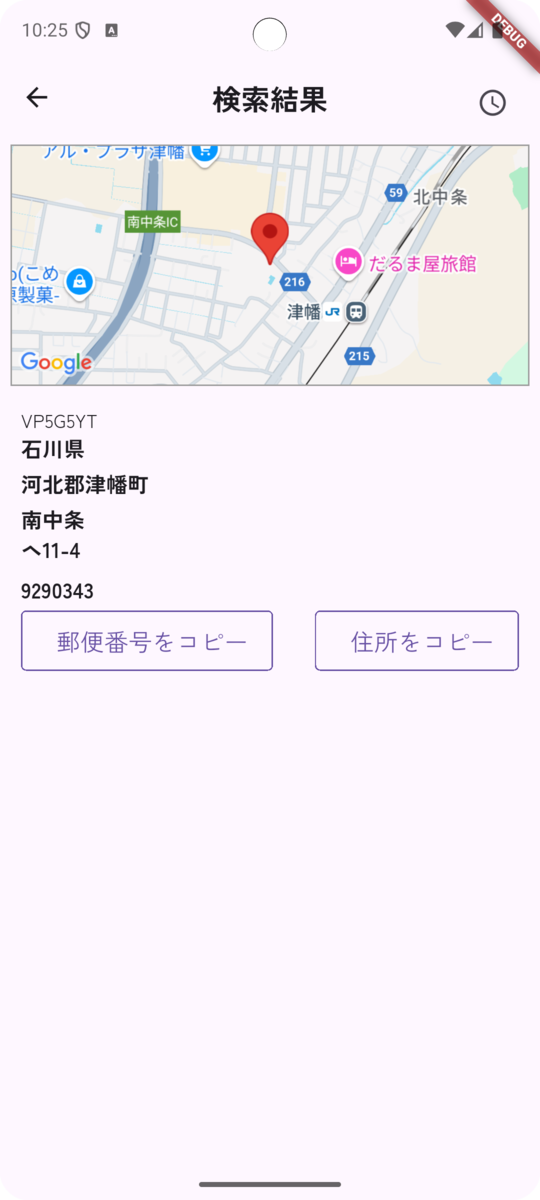
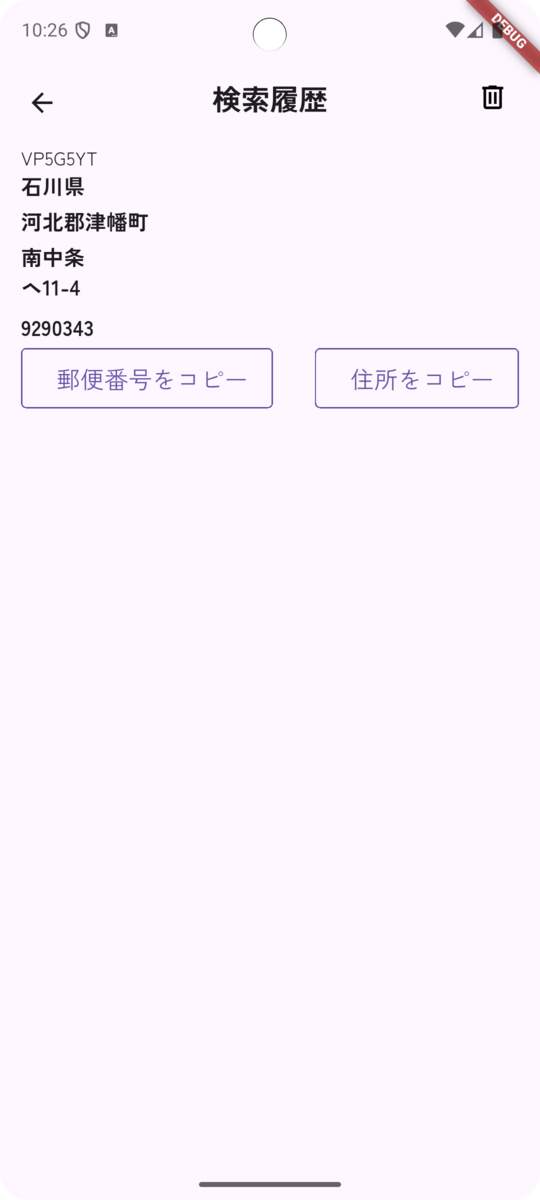
検索結果画面
登録されているデジタルアドレス、もしくは郵便番号の場合は以下のような画面が表示されます。
上から該当住所の概要マップ、住所の詳細、郵便番号および住所のコピーボタンを表示します。
この画面から住所や郵便番号をコピーして、Webサイトなどに入力するといった流れになると思います。
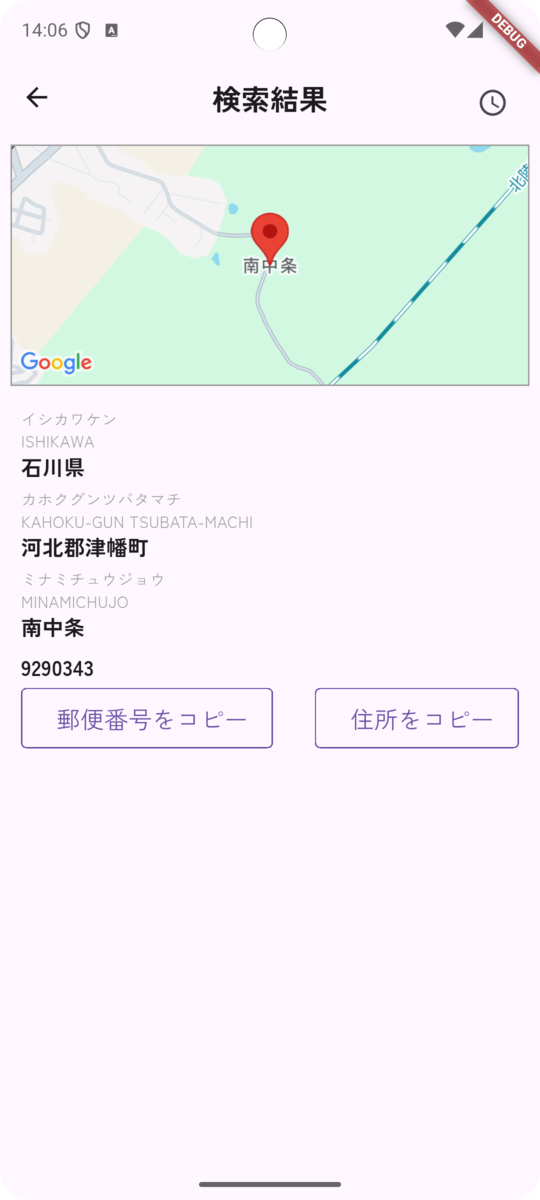
郵便番号を入力した場合は以下のようになります。
データによってはふりがなやローマ字も表示されます。
検索履歴画面
各画面から検索履歴画面を表示できます。
過去に検索した住所は、APIで通信する必要なくここで一覧表示可能です。
さらに、履歴を削除する機能もあります。
必要であれば履歴の検索機能や、履歴の個別削除の機能を実装することも可能です。
まとめ
今回のプロジェクトでは、実際にFlutterでのAPI連携・ローカルデータ保存といった一連の開発工程を体験することができ、非常に学びの多い時間となりました。
また、アプリ自体は今後も改善を重ねていく予定です。ご意見・ご感想があればぜひお気軽に弊社までお問い合わせください。
作業工程記録アプリ紹介
はじめに
こんにちは、Beta Computing株式会社ソフトウェア開発者の國田です。 この記事では作業工程記録アプリについてお話しいたします。
作業工程記録アプリのご紹介
作業の進捗や所要時間をシンプルに記録・管理できる「作業工程記録アプリ」を開発しました。
このアプリでは、作業者・作業内容・開始/完了時間を入力することで、各工程にかかった時間を記録できます。
工程ごとの所要時間を記録することで、「どの工程にどれくらい時間がかかっているか」を把握しやすくなります。
たとえば、同じ作業でも担当者や条件によって時間が異なることがありますが、そうした傾向も可視化されます。
このような情報は、業務の見直しや改善に役立てることができます。
具体的には、以下のような活用方法が考えられます。
- 時間のかかる工程を特定し、手順の見直しや補助ツールの導入を検討する
- よく似た作業の平均時間を参考にして、見積もりやスケジュールを調整する
- 作業者ごとの傾向を把握し、教育やフォローに活用する
こうした記録により、業務の属人化を防ぎ、全体の効率を見直すきっかけになります。
開発の背景
現場で作業状況を把握しようとしても、以下のような課題が生じがちです。
- 誰が、何を、どのくらいの時間で行ったのかが分かりづらい
- 作業時間の記録が手間で継続できない
- 手書きやスプレッドシートでの管理に限界がある
これらの課題を無理なく解決できるよう、必要最低限の機能に絞ってアプリを開発しました。
設計の方針
このアプリは「簡単に記録できる」ことを最優先に設計しています。
機能を絞り、操作に迷わず記録が続けやすいよう工夫しました。
アプリ使用の全体像(※想定)
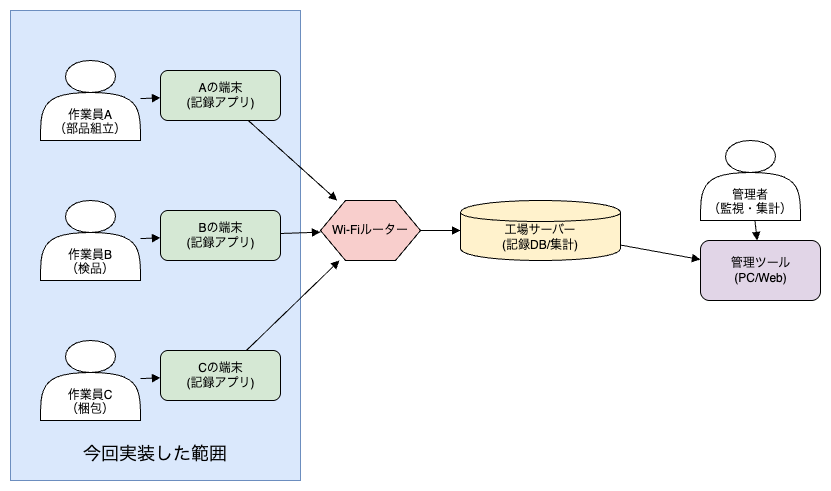
本図は、工場のライン作業において複数の作業員がそれぞれの端末を使って作業記録を行う想定のシステム構成を示しています。
作業員は、部品組立・検品・梱包といった工程ごとにそれぞれの役割を持ち、各自がスマホ端末(もしくはタブレット)を所持しています。これらの端末には作業工程記録アプリがインストールされており、作業の開始・終了などを記録することで、個々の作業時間や進捗が把握できるようになっています。
入力されたデータは、工場内のWi-Fiネットワークを通じて中継され、バックエンドの工場サーバーに送信・保存されます。これにより、作業データの一元管理が可能となり、後の分析や帳票出力、進捗モニタリングなどにも活用できます。
さらに、本構成では管理者向けの「管理ツール」の導入も想定しています。これはPCやWebブラウザ上で動作するもので、全作業員の記録状況や統計情報をリアルタイムに閲覧・分析できる機能を備えることで、現場全体の状況把握や工程の最適化を支援します。
※ なお、今回実装されているのはタブレット上の「作業工程記録アプリ」のみであり、サーバーやネットワーク、管理ツール部分については、将来的な拡張を想定した構成となっています。
主な機能
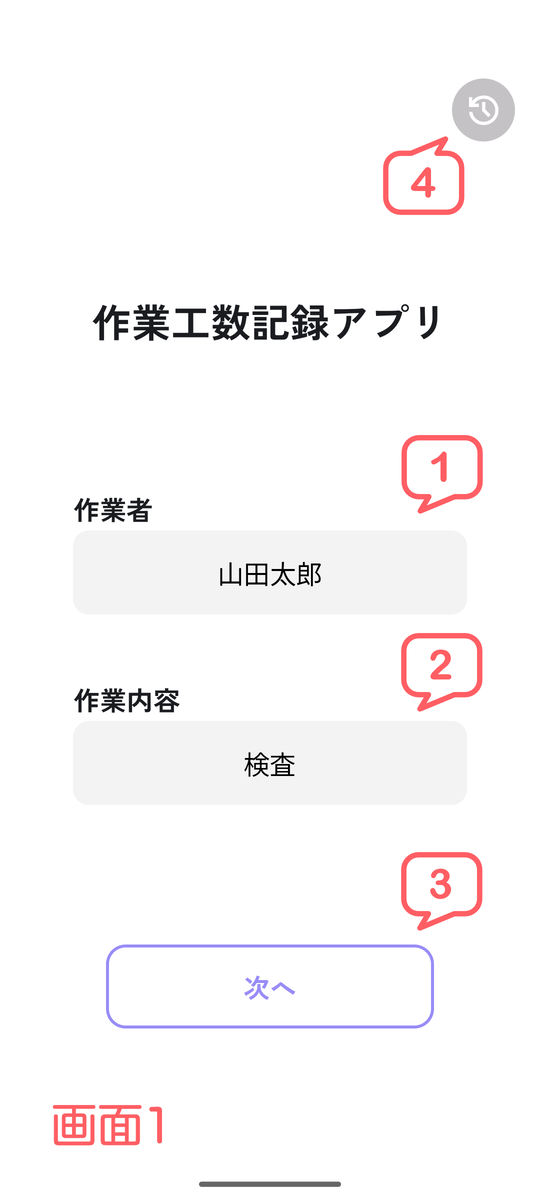
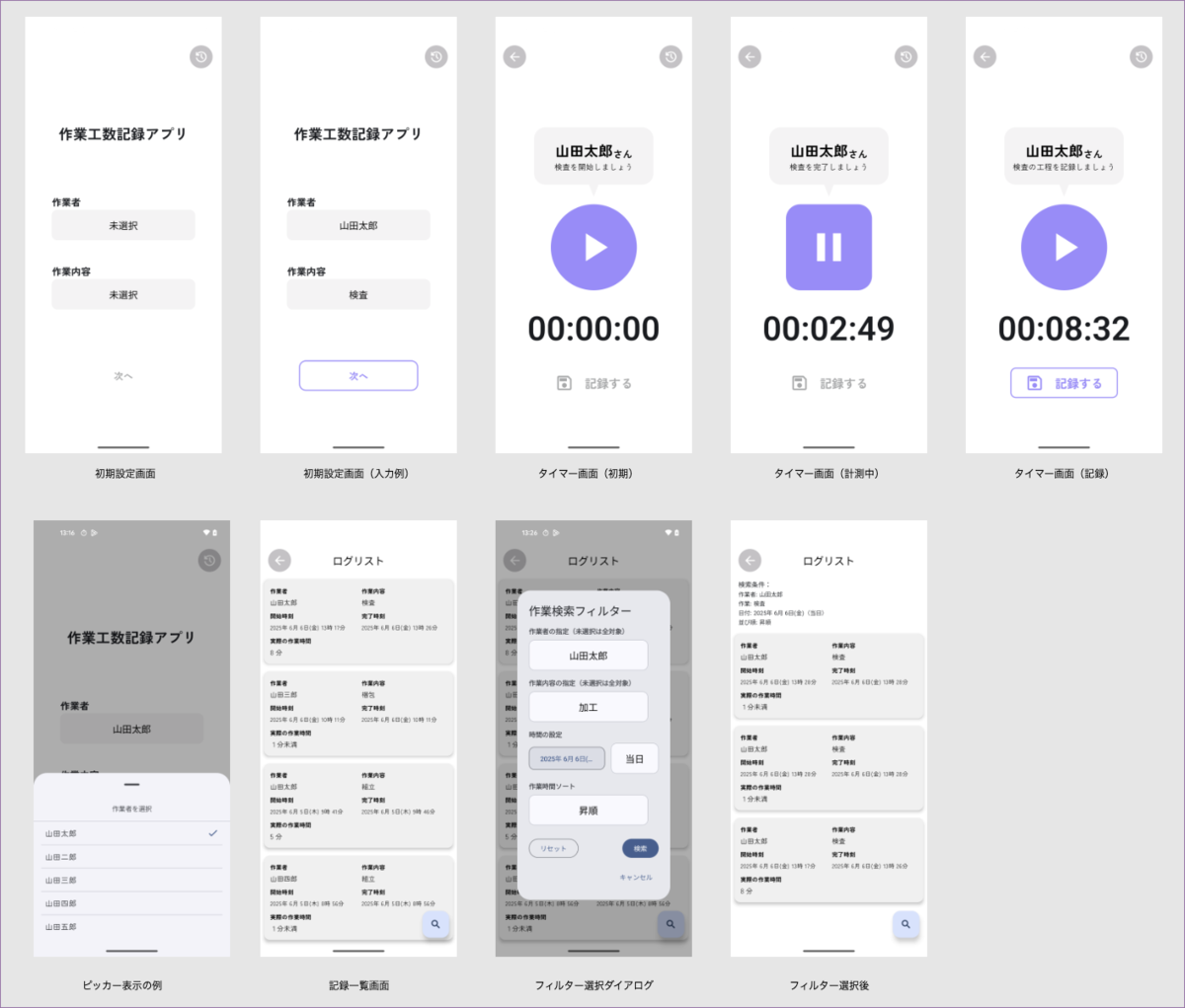
初期設定画面
作業者・作業内容の選択
作業を行った人の名前と作業内容を選択できます(画面1の1・2のボタンを押すとピッカーが表示されます)。
両方選択すると、次のタイマー画面に進みます(画面1の3のボタンで画面2へ遷移)。作業記録の確認
過去の記録も確認できます(画面1の4のボタンで遷移)。初期設定画面
ピッカー表示の例

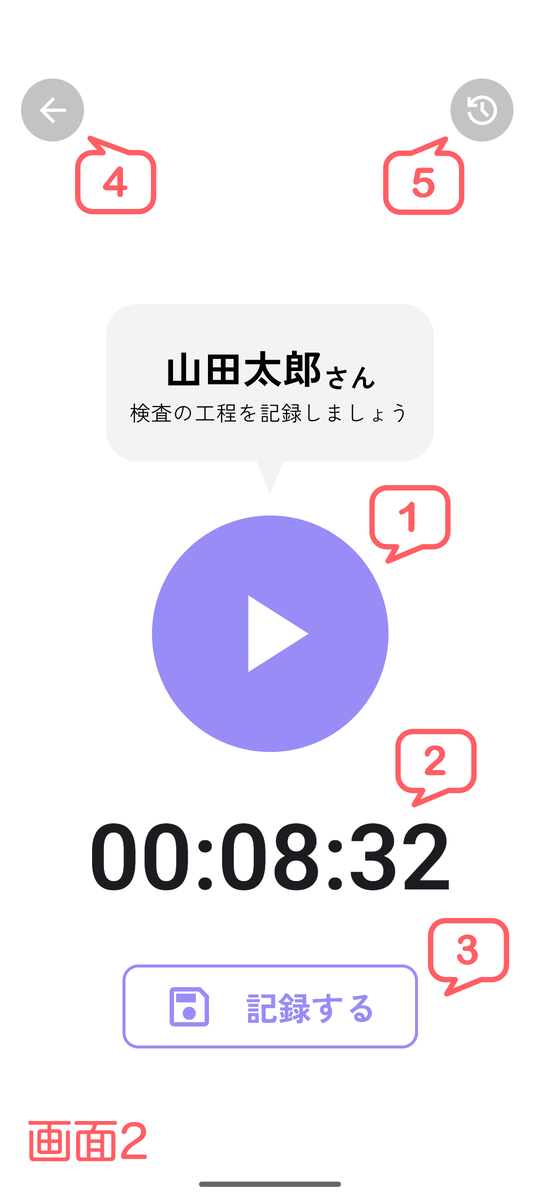
タイマー画面
タイマースタート・ストップボタン
ボタン操作で作業を開始・完了(ポーズ)できます(画面2の1のボタン)。ポーズ機能
作業を中断・休憩したい場合、一時停止できます。再度ボタンを押すと作業が再開され、この中断時間は作業時間に含まれません(画面2の1のボタン)。経過時間表示
開始からの作業時間がリアルタイムで表示されます(画面2の2の表示)。作業内容の記録
タイマーをストップした後、作業内容を記録できます(画面2の3のボタン)。記録の確認・破棄
記録一覧を確認したり、設定を変更してやり直したり、記録を破棄したりできます(画面2の4及び5のボタン)。タイマー画面
記録一覧表示画面(お試し実装)
一覧表示
過去の作業記録を一覧で確認できます。
フィルター検索機能
様々な条件を追加して過去の記録を絞ることができます。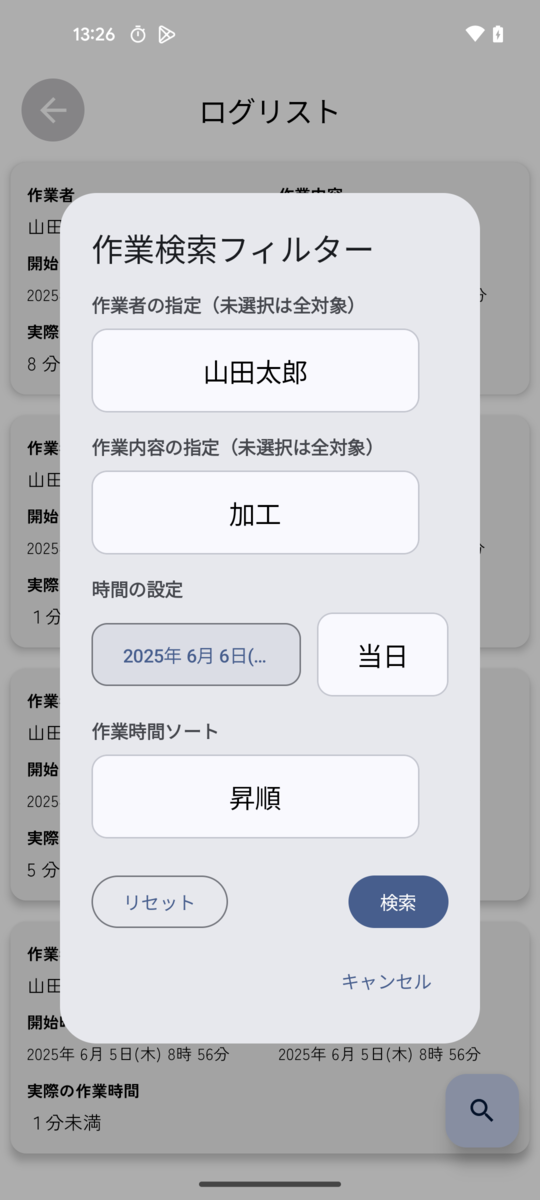
今後の展開
今後の需要次第では、以下のような機能追加も検討しています。
- 作業内容のカテゴリ分けやタグ付け
- 記録データのCSV出力
- 集計や簡単なグラフ表示
- サーバーによるデータの一括管理
おわりに
作業時間を正確に把握することは、無理のない業務改善の第一歩です。
日々の業務の中で自然に「見える化」できるよう、記録のハードルを下げることを目指しています。
本アプリやその導入にご関心をお持ちいただけましたら、どうぞお気軽に弊社までお問い合わせください。
おまけ
画面一覧です。
端末管理アプリ ~ 技術仕様 ~
この記事について
こんにちは、Beta Computing株式会社ソフトウェア開発者の尾崎です。
前の記事に引き続き、この記事では端末管理アプリの技術仕様についてお話しいたします。
システム構成
本アプリは以下の3つの要素から構成されます。
- iOSアプリ
- 端末情報を登録、貸出、返却するためのUIを提供
- Firebase(クラウドバックエンド)
- 端末情報、貸出状況等を保存するためのデータサーバ
- NFCタグ
- 端末識別のための物理タグ
- 各端末に貼り付け、iOSアプリで読み取り可能とする
- 書き込む情報は変動しないデータのみ(書き込み操作を初回のみとするため)
- デバイスID、モデル名、シリアル番号
システム構成図

シーケンス図
例1. 端末情報更新 + NFCタグ登録
sequenceDiagram participant User as ユーザ participant App as iOSアプリ participant Firebase as Firebase User ->> App: 端末一覧タブをタップ App ->> User: 端末一覧画面を表示 App ->> Firebase: 端末情報リストを読み込み Firebase ->> App: 読み込み成功レスポンス App ->> User: 端末情報リストを表示 User ->> App: 端末情報セルをタップ App ->> User: 端末詳細情報画面を表示 App ->> Firebase: 更新履歴を読み込み Firebase ->> App: 読み込み成功レスポンス App ->> User: 更新履歴を表示 User ->> App: 編集ボタンをタップ App ->> User: 端末情報入力画面を表示 User ->> App: 状態、OSバージョンなど入力 App ->> App: 入力状況をチェックして保存ボタンを活性制御 User ->> App: 保存ボタンをタップ App ->> Firebase: 端末情報を書き込み Firebase ->> App: 書き込み成功レスポンス App ->> User: UI更新 User ->> App: NFCスキャンボタンをタップ App ->> User: NFCモーダルを表示 User ->> NFC: NFCタグをスキャン NFC ->> App: 読み込み成功レスポンス App ->> App: タグ内のデータをチェック App ->> User: 書き込み準備完了ダイアログを表示 User ->> App: 書き込み実行ボタンをタップ App ->> User: NFCモーダルを表示 User ->> NFC: NFCタグをスキャン NFC ->> App: 書き込み成功レスポンス App ->> Firebase: 該当端末をNFC登録済に更新 Firebase ->> App: 更新成功レスポンス App ->> User: UI更新
例2. 端末貸出申請
sequenceDiagram participant User as ユーザ participant App as iOSアプリ participant Firebase as Firebase participant NFC as NFCタグ User ->> App: 貸出状況タブをタップ App ->> User: 貸出中端末一覧画面を表示 App ->> Firebase: 貸出状況リストを読み込み Firebase ->> App: 読み込み成功レスポンス App ->> User: 貸出状況リストを表示 User ->> App: 申請ボタンをタップ App ->> User: 貸出返却処理メニューを表示 User ->> App: NFCスキャンボタンをタップ App ->> User: NFCモーダルを表示 User ->> NFC: NFCタグをスキャン NFC ->> App: 読み込み成功レスポンス App ->> App: タグ内のデータをチェック App ->> Firebase: 該当端末の貸出状況を読み込み Firebase ->> App: 読み込み成功レスポンス App ->> User: 貸出申請画面を表示 App ->> Firebase: ユーザ情報リストを読み込み Firebase ->> App: 読み込み成功レスポンス App ->> User: ユーザ情報をUIに反映 App ->> App: ユーザ選択状況をチェックして申請ボタンを活性制御 User ->> App: ユーザを選択して申請ボタンをタップ App ->> Firebase: 貸出状況を更新 Firebase ->> App: 更新成功レスポンス App ->> User: UI更新
使用フレームワーク・ライブラリ
| 名称 | 説明 |
|---|---|
| CoreNFC | NFCタグの読み取り/書き込みを行うためのフレームワーク |
| Network | ネットワーク接続状況を監視するためのフレームワーク |
| FirebaseCore | Firebaseの基盤ライブラリで、アプリ起動時の初期化処理を行う |
| FirebaseFirestore | Cloud Firestoreとの通信・データ操作を行うためのライブラリ |
| RxSwift | 非同期処理や状態管理のためのライブラリ |
| RxCocoa | UIイベントとRxSwiftの連携を行うライブラリ |
| XCGLogger | ログ出力(開発・デバッグ用)の管理ライブラリ |
| SwiftLint | Swiftコードのスタイルチェックと静的解析ツールライブラリ |
アーキテクチャ設計
設計はSwiftUI + MVVM(Model-View-ViewModel)アーキテクチャを採用しています。
- View
- ユーザーインターフェースの定義(SwiftUI)
- ViewModel
- 状態管理とロジック処理
- 各Viewに対して1つのViewModel
- Model
- データ構造
- 共通ユーティリティクラス
- Firestoreとのやり取り
- NFCタグの読み取り/書き込み
- ネットワーク接続状況の監視
View-ViewModelの構成
ViewとViewModelは1対1とし、機能ごとに責務を分離して保守性とテスト容易性を高めることを目的としています。
実装例
struct RentalView: View { @StateObject var viewModel = RentalViewModel() // UIの定義 }
final class RentalViewModel: ObservableObject { @Published var rentals: [RentalModel] = [] func fetchRentals() {...} }
共通ユーティリティクラスについて
複数のViewModelやViewから共通的に利用される機能を、以下3つのユーティリティクラスとして分離し、それぞれシングルトンパターンで管理しています。
DataManagerクラス
- Firebase/Firestore関連の操作を集約
- CRUD操作の共通化、エラーハンドリングの一元化が目的
final class DataManager { static let sharedInstance = DataManager() private let db = Firestore.firestore() private init() {} func fetchDevices() -> [DeviceModel] { ... } func saveDevice(...) { ... } // 他にも貸出返却処理・更新履歴保存など... }
NFCManagerクラス
CoreNFCを使用してNFCタグの読み取り/書き込みを管理- ViewModelとは独立して動作し、デリゲートパターンで結果を返す
final class NFCManager: NSObject, ObservableObject, NFCNDEFReaderSessionDelegate { static let sharedInstance = NFCManager() private override init() {} weak var delegate: NFCManagerDelegate? func readerSession(...) {...} }
NetworkMonitorクラス
- ネットワーク接続状況の監視を担当
- オフライン時にサーバへの書き込みを制限するため使用
NWPathMonitorを使用してリアルタイムで監視を行う
final class NetworkMonitor { static let sharedInstance = NetworkMonitor() private let monitor = NWPathMonitor() private let queue = DispatchQueue(label: "NetworkMonitor") private(set) var isConnected: Bool = false private init() { monitor.pathUpdateHandler = { [weak self] path in self?.isConnected = path.status == .satisfied } monitor.start(queue: queue) } }
これらのクラスはアプリ全体にわたって一貫した状態・動作が求められるため、final class+private init()により、インスタンスを1つに限定することで整合性を実現しています。
データモデル設計
Cloud Firestoreでは端末情報・更新履歴・貸出情報・貸出履歴・ユーザ情報を各コレクションに分けて管理しています。アプリ側のModelは各ドキュメントに対応するモデル設計としています。
独立したデータとして保存することで、端末やユーザ情報を削除しても履歴には残るという仕様にしています。
DeviceModel(端末情報)
struct DeviceModel: Codable, Identifiable, Hashable { @DocumentID var id: String? var group: String // グループ(Androidスマホ、iPhoneなど) var model: String // 端末名 var serialNumber: String // シリアル番号 var osVersion: String // OSバージョン var status: String // 状態(正常、故障、廃棄) var connectorType: String // コネクタ形状 var registeredAt: Date // 登録日 var isRental: Bool // 現在貸出中ならtrue var note: String? // 備考 var isNFCRegistered: Bool? = false // NFCタグ登録済みならtrue }
DeviceLogModel(更新履歴)
struct DeviceLogModel: Codable, Identifiable { @DocumentID var id: String? var deviceId: String // 端末ID var operationType: String // 操作種別(新規追加、更新、削除) var field: String // 操作対象 var oldValue: String? // 変更前の値 var newValue: String? // 変更後の値 var registeredAt: Date // 登録日 }
RentalModel(貸出情報、貸出履歴)
struct RentalModel: Codable, Identifiable { @DocumentID var id: String? var deviceId: String // 端末ID var model: String // 端末名 var osVersion: String // OSバージョン var serialNumber: String // シリアル番号 var userId: String // ユーザID var userName: String // ユーザ名 var rentedAt: Date // 貸出日 var returnedAt: Date? // 返却日 }
UserModel(ユーザ情報)
struct UserModel: Codable, Identifiable { @DocumentID var id: String? var name: String // ユーザ名 var registeredAt: Date? // 登録日 }
おわりに
今回作成したアプリはクラウドデータベースとNFC技術を活用することで、シンプルかつ正確な端末管理を目指した設計となっています。実装面でも機能ごとに切り分けてコードを記述することで、今後の拡張性やメンテナンス性も意識した開発ができたかと思います。
前の記事でも触れましたが、ViewをSwiftUIで実装したことで、ダークテーマや画面回転にも対応した柔軟なデザインが簡潔に記述できるのは非常に良い点だと感じました。
今後も継続してアプリ開発に尽力し、より良いサービスを開発できるよう努めたいと思います。
ここまでお読みいただき、ありがとうございました。